RealSinger
Aspect technique
|
 |
Note
:
Cette page
n'est qu'une courte vue d'ensemble des méthodes utilisées
par RealSinger pour générer la voix.
Ce n'est pas
nécessaire de lire ceci pour pouvoir utiliser RealSinger.
Ce chapitre
est destiné à répondre aux questions techniques que
pourraient se poser certains utilisateurs quant aux algorithmes internes,
et n'est donc pas nécessaire pour utiliser le produit. |
|
Introduction
|  |
|
|
Pour produire une synthèse vocale
chantée réaliste, la première idée qui vient
à l'esprit du programmeur est d'utiliser une collection de phonèmes
enregistrés pour générer la voix.
Trois problèmes apparaissent
rapidement :
-
L'algorithme doit être capable
de générer le phonème à n'importe quelle fréquence.
Enregistrer tous les phonèmes possibles à toutes les fréquences
possibles n'est pas envisageable, car cela conduirait à un processus
d'enregistrement long et complexe, ainsi que des fichiers de définition
de voix très volumineux.
-
L'algorithme doit pouvoir prolonger
le phonème autant que désiré.
-
L'algorithme doit être capable
de générer une transition douce entre un phonème et
un autre, afin de simuler le phénomène de coarticulation
(le phonème suivant commence à être entendu alors
que le précédent n'est pas encore complètement terminé).
Dans la littérature informatique,
une solution peut être trouvée pour chacun de ces problèmes
Pour les problèmes 1 et 2,
quelques algorithmes efficaces ont déjà été
développés. Ils traitent directement le signal numérique
de l'échantillon enregistrée et permettent de changer la
fréquence aussi bien que la durée. Ces algorithmes sont utilisés
dans la plupart des éditeurs de son, pour changer la fréquence
ou la durée d'un fichier sonore de manière indépendante.
Ils sont également utilisés avec succès en synthèse
vocale parlée car les variations de fréquence sont assez
faibles dans ce cas.
Cependant, en voix chantée,
ces algorithmes ne peuvent pas être utilisés car ils ne sont
plus efficaces dans le cas de changement de fréquence trop importants.
Le résultat n'est pas "faux" en lui-même, mais la voix est
déformée, exactement comme quand une bande magnétique
défile trop vite (voix de canard).
Pour le
problème 3, une solution courante est de ne pas enregistrer seulement
les phonèmes d'une langue, mais toutes les combinaisons possibles
de deux ou trois phonèmes (diphonemes, triphonemes).
Ce système stocke les coarticulations et rend la voix synthétisée
plus réaliste. Cependant, ici encore, le processus d'enregistrement
est assez long et compliqué, et nécessite souvent de la part
du locuteur (chanteur) plusieurs heures d'enregistrement. Le fichier définissant
la voix est souvent assez imposant (plusieurs méga-octets)
RealSinger utilise des algorithmes
originaux pour résoudre ces trois problèmes à la fois,
en manipulant les spectres de fréquence.
Certains synthétiseur vocaux
ont déjà essayé d'utiliser les spectres de fréquence
pour générer la voix.
Cependant, cette méthode
s'est avérée difficile à mettre en oeuvre car régénerer
un signal à partir d'un spectre en utilisant une transformée
de Fourier inverse rapide (IFFT) nécessite de réajuster correctement
les valeurs de "phase", sinon les morceaux consécutifs de signal
ne se joignent pas correctement, et un bruit de fond est perceptible.
Spectre vocal
| | |
|
|
Quand on parle ou qu'on chante, la forme
d'onde de la source glottale (son produit par les cordes vocales lorsqu'elles
sont excitées par le flux d'air venant des poumons) est une combinaison
d'harmoniques (fréquences multiples de celles de la fondamentale
f0)
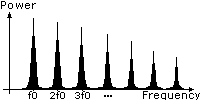
Dans un graphe puissance/fréquence,
le signal produit par la source glottale ressemble à un peigne,
chaque dent du peigne étant localisé à un multiple
de la fondamentale f0:
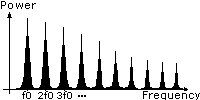
Quand la
fréquence de la voix augmente, f0 glisse vers la droite (hautes
fréquences) et la différence de fréquence entre deux
harmoniques consécutives augmente également, pour rester
égale à f0.
 En passant à travers le conduit
vocal, les résonances des cavités mettent en valeur certaines
fréquences, et en amortissent d'autres. Le résultat est que
certaines harmoniques sont puissantes, et d'autres sont amorties. Ce spectre
de réponse du conduit vocal dépend du phonème prononcé
ou chanté, et reste plus ou moins inchangé quand la fréquence
augment ou diminue.
En passant à travers le conduit
vocal, les résonances des cavités mettent en valeur certaines
fréquences, et en amortissent d'autres. Le résultat est que
certaines harmoniques sont puissantes, et d'autres sont amorties. Ce spectre
de réponse du conduit vocal dépend du phonème prononcé
ou chanté, et reste plus ou moins inchangé quand la fréquence
augment ou diminue.
 La convolution de ces deux spectres
(source et conduit vocal) donne le spectre résultat, dans lequel
la personne qui écoute peut déterminer à la fois le
phonème (ce qui est dit) et la fréquence (note chantée)
La convolution de ces deux spectres
(source et conduit vocal) donne le spectre résultat, dans lequel
la personne qui écoute peut déterminer à la fois le
phonème (ce qui est dit) et la fréquence (note chantée)
Les bases de RealSinger
| | |
|
|
Le but de RealSinger est, pour chaque
phonème d'une langue donnée, d'appliquer une déconvolution
au signal enregistré afin de séparer les spectres de la source
glottale et du conduit. Alors, seulement le spectre du conduit est stocké.
Une source glottale artificielle sera appliquée à ce spectre
pour simuler le phonème original enregistré chanté
à n'importe quelle fréquence.
Processus d'enregistrement | | |
-
Il est demandé à l'utilisateur
de prononcer un mot pour chacun des phonèmes de la langue choisie
-
Chaque mot est enregistré en
données sonores traditionnelles
-
Alors, le phonème est isolé
dans le mot, et le signal est recadré afin de ne conserver que cette
partie
-
Un spectre moyen de ce son est calculé.
-
Ce spectre est déconvolué
pour supprimer l'influence de la source glottale, et de ne garder que la
courbe de fréquence des résonances du conduit vocal.
-
Ce pseudo-spectre est stocké
(moins de 100 valeurs pour chaque phonème)
-
Pour les phonèmes qui varient
dans le temps comme les plosives, plusieurs pseudo-spectres sont stockés
pour conserver les informations sur les changements dans le spectre.
Ces algorithmes permettent de ne stocker
qu'un petit nombre de données pour chaque spectre, ce qui permet
d'obtenir des fichiers de définition de voix très courts
(moins de 40 Ko par voix une fois compressé)
Generation de la voix | | |
-
Pour chaque phonème à
chanter, le pseudo-spectre correspondant est extrait. Dans les parties
transitionnelles entre deux phonèmes, les deux pseudo-spectres sont
déformés et mixés ensemble pour simuler le processus
de coarticulation.
-
Un signal synthétique de source
glottale synthétique est généré à la
fréquence désirée. Le spectre glottal de la source
peut être aisément modifié pour changer le timbre global
de la voix (pour égaliser, ou appliquer divers effets de type vocoder).
-
Cette source est re-convoluée
avec le pseudo-spectre du phonème.
-
Ce spectre est alors traité par
une transformée inverse sans phase, pour générer un
bloc de données sonores standard.
Cet algorithme simule les effets de
coarticulation. De ce fait, il n'est pas nécessaire d'enregistrer
le jeu complet des diphonèmes et triphonèmes. Seul un jeu
de monophonèmes est requis.
|

 Page précédente
Page précédente